



【MySQL】索引
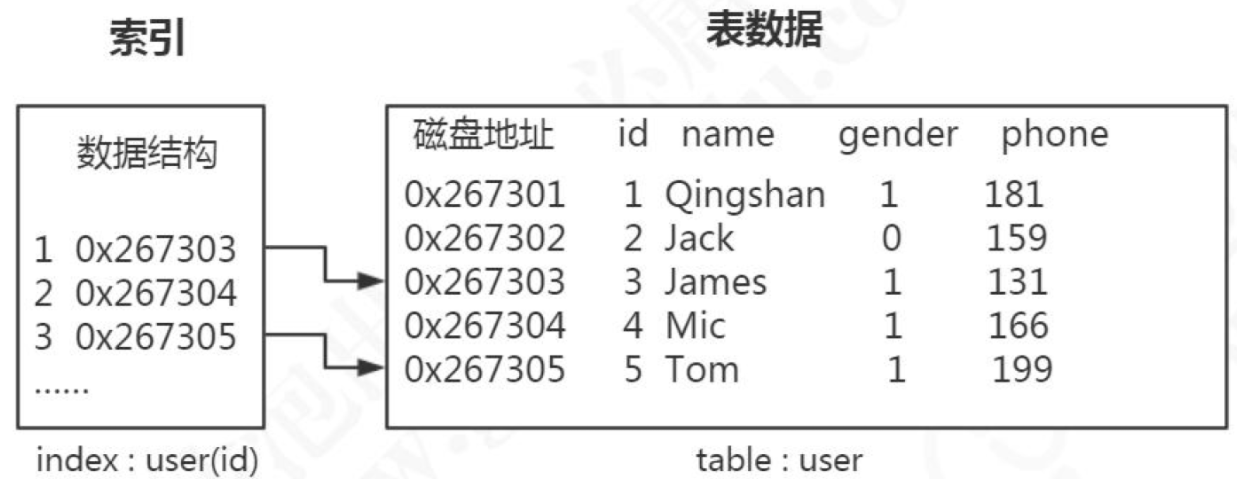
索引是什么
定义
数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、更新数据库表中数据。
类型
普通(Normal)
也叫非唯一索引,是最普通的索引,没有任何的限制。
create table m1 (
id int,
index(id)
) ;
ALTER TABLE table_name ADD INDEX index_name(column);
唯一(Unique)
唯一索引要求键值不能重复。
主键索引是一种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键索引用primay key创建。
create table m2 (
id int,
unique index(id)
);
create unique index IX_GoodsMade_Labour on GoodsMade_Labour(SID)
ALTER TABLE `table_name` ADD UNIQUE (`column`)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
全文(Fulltext)
针对比较大的数据,比如我们存放的是消息内容,有几KB的数据的这种情况,如果要解决like查询效率低的问题,可以创建全文索引。
只有文本类型的字段才可以创建全文索引,比如char、varchar、text。
create table m3 (
name varchar(50),
fulltext index(name)
);
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
select * from m3 where match(name) against('测试' IN NATURAL LANGUAGE MODE);
索引存储模型推演
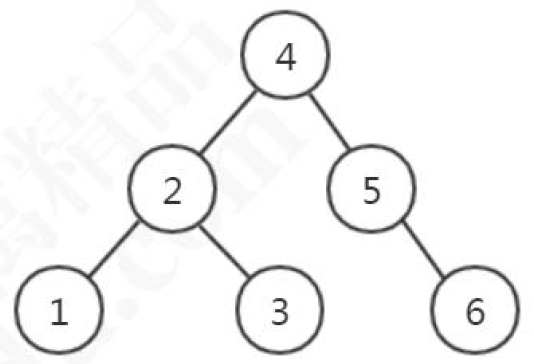
二叉树(BST)
左子树所有的节点都小于父节点,右子树所有的节点都大于父节点。投影到平面以后,就是一个有序的线性表。
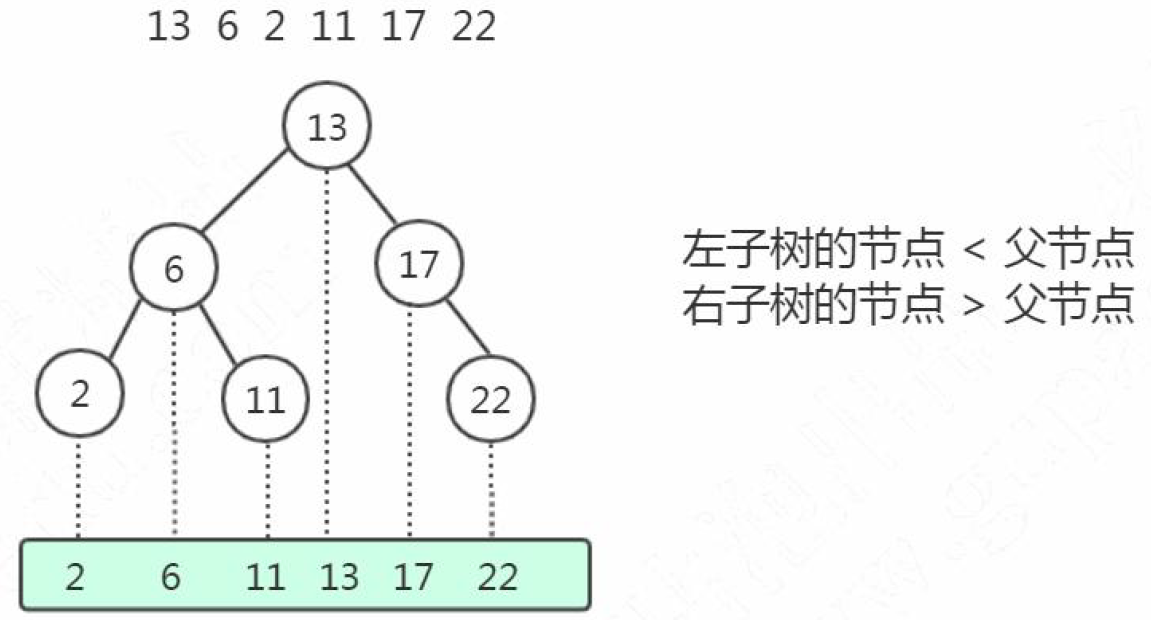
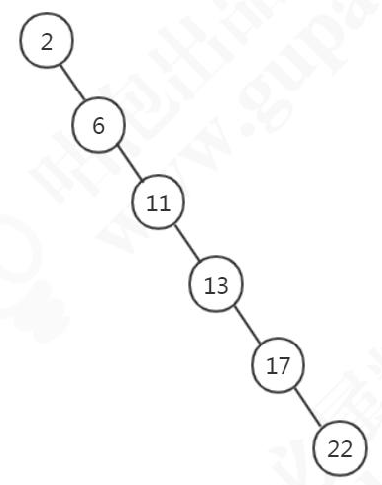
它的查找耗时是和这棵树的深度相关的,在最坏的情况下时间复杂度会退化成O(n)。
平衡二叉树(AVL Tree)
左右子树深度差绝对值不能超过1。比如左子树的深度是2,右子树的深度只能是1或者3。
左旋操作

右旋操作

树节点存储内容
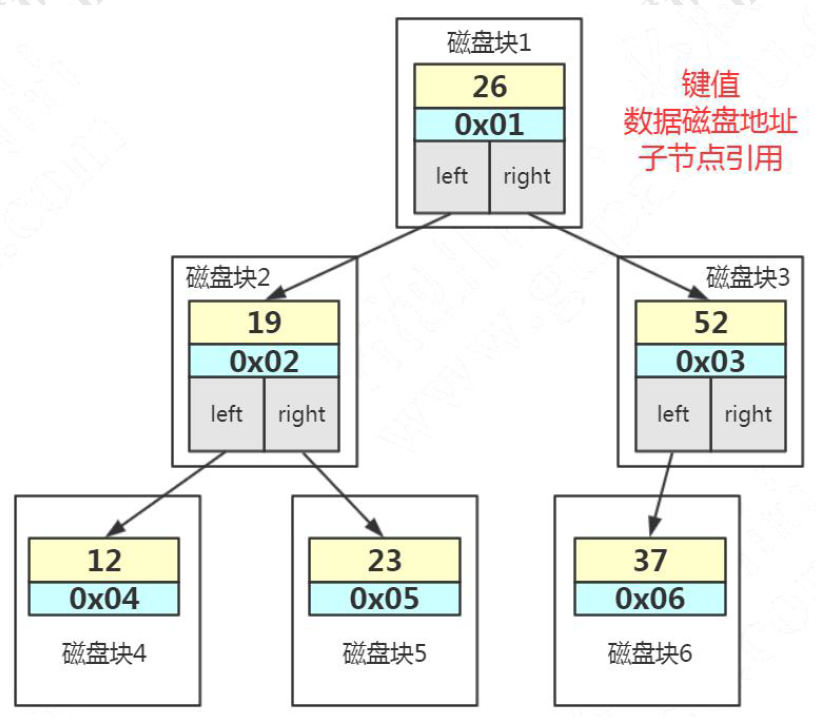
- 索引的键值
- 数据的磁盘地址
- 左子节点和右子节点的引用
InnoDB逻辑存储结构
InnoDB逻辑存储结构分为5级:表空间、段、簇、页、行。
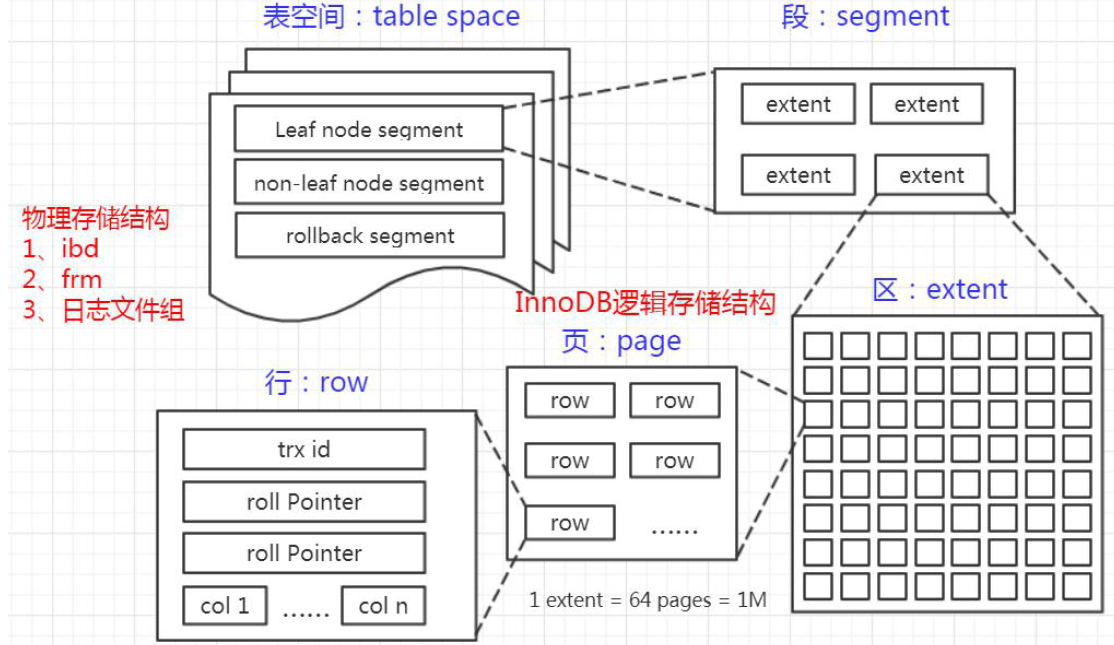
表空间(Table Space)
InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。分为:系统表空间、独占表空间、通用表空间、临时表空间、Undo表空间。
段(Segment)
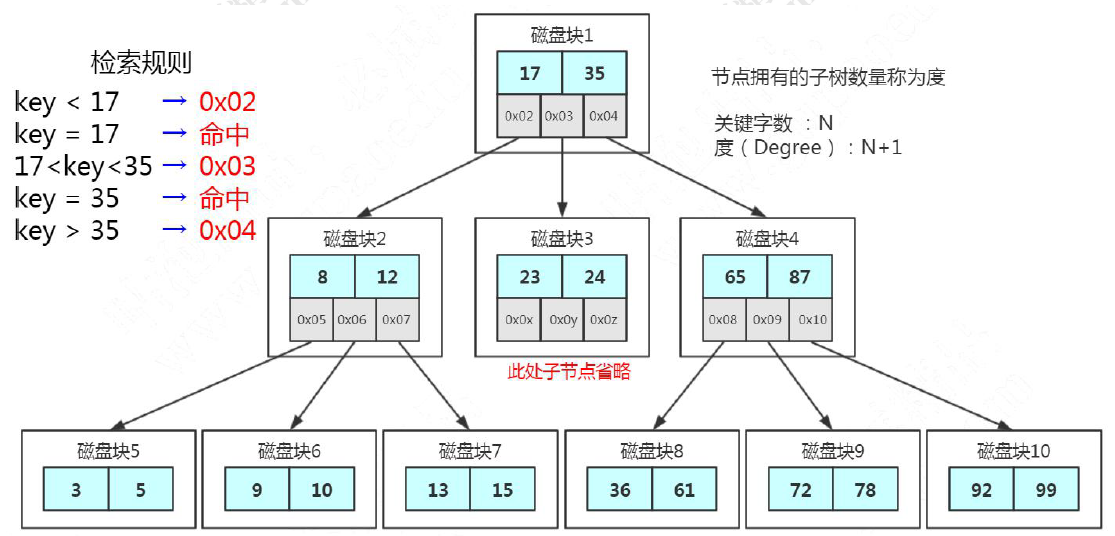
多路平衡查找树(B Tree)
分叉数(路数)永远比关键字数多1
加强版多路平衡查找树(B+ Tree)
红黑树
索引存储模型分析
索引使用原则
列的离散度
公式
count(distinct(column_name)) : count(*)
列的全部不同值和所有数据行的比例。列的重复值越多,离散度就越低,重复值越少,离散度就越高。
查看一个表上的索引
show indexes from user_innodb
Cardinality [kɑ:dɪ'nælɪtɪ]:预估的不重复的值的数量。索引的基数与表总行数越接近,列的离散度就越高。
总结
建立索引,要使用离散度(选择度)更高的字段。
联合索引最左匹配
创建联合索引
ALTER TABLE user_innodb add INDEX comidx_name_phone (name, phone);
联合索引数据结构
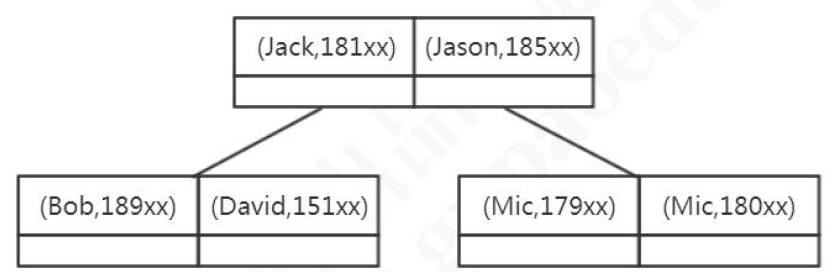
- 按照从左到右的顺序来建立搜索树的(name在左边,phone在右边)。
- name是有序的,phone是无序的。当name相等的时候,phone才是有序的。
- 如果查询条件没有name,用不到索引。
- 如果查询条件是
where phone=? and name=?依然会用到这个索引,查询优化器会帮我们优化查询条件。
总结
- 在建立联合索引的时候,一定要把最常用的列放在最左边。
- 如果我们创建三个字段的索引
index(a,b,c),相当于创建三个索引:index(a),index(a,b),index(a,b,c),用where b=?和where b=? and c=?和where a=? and c=?是不能使用到索引的。不能不用第一个字段,不能中断。
覆盖索引
回表
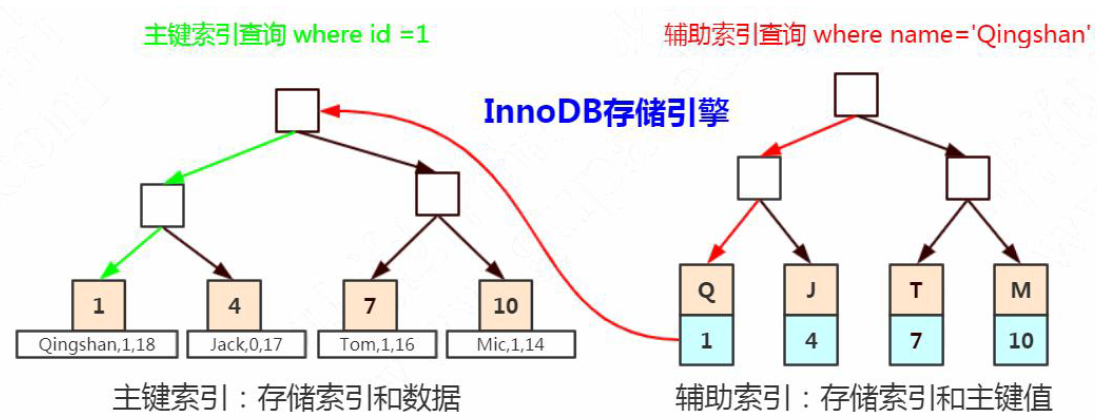
非主键索引,我们先通过索引找到主键索引的键值,再通过主键值查出索引里面没有的数据,它比基于主键索引的查询多扫描了一棵索引树。
覆盖索引
在辅助索引里面,不管是单列索引还是联合索引,如果select的数据列只用从索引中就能够取得,不必从数据区中读取,这时候使用的索引就叫做覆盖索引

Extra里面值为
Using index代表使用了覆盖索引。
总结
- 覆盖索引减少了IO 次数,减少了数据的访问量,可以大大地提升查询效率。
- 避免使用
select *来查询。
索引条件下推(ICP)
概念
Server层将where条件下推给存储引擎,用于二级索引的过滤,从而减少访问表的完整行的读数量。如下图所示:
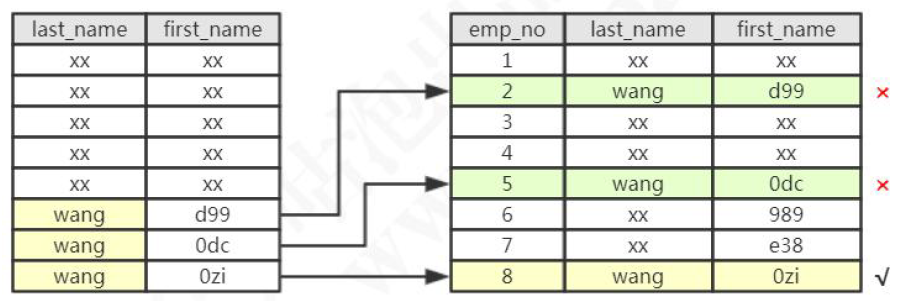
如果我们要查询where last_name='wang' and first_name like '%zi',当开启ICP的话,可以直接在存储引擎里面过滤掉不符合条件的二级索引,然后再进行回表查询完整行数据。
修改和查看ICP
-- 修改ICP
set optimizer_switch='index_condition_pushdown=on';
-- 查看ICP
show variables like 'optimizer_switch';
查看SQL查询是否使用ICP

Extra里面值为
Using index condition代表使用了ICP。
索引的创建和使用
索引的创建原则
- 在用于where判断,order排序和join的(on)字段上创建索引
- 索引的个数不要过多,如果太多浪费空间,更新变慢
- 离散度低的字段,例如性别,不要建索引
- 频繁更新的值,不要作为主键或者索引
- 组合索引把散列性高(区分度高)的值放在前面
- 创建复合索引,而不是修改单列索引
- 过长的字段,怎么建立索引?使用
前缀索引 - 为什么不建议用无序的值(例如身份证、UUID )作为索引?创建索引的时候会出现频繁的B+ Tree分裂。
什么时候用不到索引
一个SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。其实,用不用索引,最终都是优化器说了算,优化器是基于cost开销(Cost Base Optimizer),它不是基于规则(Rule-Based Optimizer),也不是基于语义。怎么样开销小就怎么来。
- 索引列上使用函数(replace/substr/concat/sum/count/avg)、表达式、计算(+ - * /)
- 字符串不加引号,出现隐式转换
- LIKE条件中前面带%
- 负向查询
- NOT LIKE
- !=(<>)和NOT IN在某些情况下可以
评论区